1. Introduction
The fine-tuning argument is regarded as one of the strongest arguments for the existence of God in contemporary philosophy of religion, the cutting-edge in the long tradition of design arguments for God.
In his article in the Blackwell Companion to Natural Theology, Robin Collins states the core fine-tuning argument thus (edited here only to expand Collins’ acronyms): (p. 6)
(1) Given the fine-tuning evidence, a life-permitting universe (LPU) is very, very epistemically unlikely under Naturalism and a single universe (NSU): that is, P(LPU|NSU & k′) << 1, where k′ represents some appropriately chosen background information, and << represents much, much less than (thus making P(LPU|NSU & k′) close to zero).
(2) Given the fine-tuning evidence, LPU is not unlikely under Theism (T): that is, ~P(LPU|T & k′) << 1.
(3) T was advocated prior to the fine-tuning evidence (and has independent
motivation).
(4) Therefore, by the restricted version of the Likelihood Principle, LPU strongly supports T over NSU
In this article, I will examine the argument Collins uses to defend (1), and argue that his argument makes a faulty assumption.
2. Arguing for (1)
The core support for (1) is of course the fine-tuning evidence. A discussion of such evidence is far beyond the scope of this article, so on this topic I will refer the reader to the discussion in Collins’ article and to the excellent and detailed discussion by astronomer Luke Barnes.
The gist of this evidence is that in order for life to be possible in our universe, given our best understanding of physics, the fundamental constants of our universe must lie within extremely narrow intervals, relative to the range of values that a priori they might have taken.
2.1. The Principle of Indifference
How do you get from “narrow intervals” to “low probability”? To do this, you must assume some probability distribution on the possible values the fundamental constants could have taken. Towards this, Collins introduces the following principle: (p. 33)
According to the restricted Principle of Indifference, when we have no reason to prefer any one value of a variable p over another in some range R, we should assign equal epistemic probabilities to equal ranges of p that are in R, given that p constitutes a “natural variable.” A variable is defined as “natural” if it occurs within the simplest formulation of the relevant area of physics.
[…]
Since the constants of physics used in the fine-tuning argument typically occur within the simplest formulation of the relevant physics, the constants themselves are natural variables. Thus, the restricted Principle of Indifference entails that we should assign epistemic probability in proportion to the width of the range of the constant we are considering. We shall use this fact in Section 5.1 to derive the claim that P(Lpc|NSU & k′) << 1, where Lpc is the claim that the value for some fine-tuned constant C falls within the life permitting range.
In other words, Collins argues that we have no reason to think any values of the fundamental constants are a priori any more likely than any other, and so we should assume a uniform distribution on the possible values of the constants. He then later argues for (1) as follows: (p. 51)
(i) Let C be a constant that is fine-tuned, with C occurring in the simplest current formulation of the laws of physics. Then, by the definition of fine-tuning, Wr/WR << 1, where Wr is the width of the life-permitting range of C, and WR is the width of the
comparison range, which we argued was equal to the width of the Epistemically Illuminated range [the range of values for which physics tells us whether those values are life permitting].
(ii) Since NSU and k′ give us no reason to think that the constant will be in one part of the EI range instead of any other of equal width, and k′ contains the information that it is somewhere in the EI range, it follows from the restricted Principle of Indifference that P(Lpc|NSU & k′) = Wr/WR, which implies that P(Lpc|NSU & k′) << 1.
This assumption of a uniform distribution will be our target in this article. However, before we delve into that, it will be good to briefly review the virtues of the Principle of Indifference. Given no information, a uniform distribution is the most natural to assume, precisely because it does not arbitrarily favour any particular outcome over any other for no good reason. Furthermore, a uniform distribution is what you get when you average over all distributions that might govern the outcome.
This latter perspective is going to be important in what follows, so let us be explicit about it. We will suppose that our fine-tuned constant 

3. Things we know about the distribution
However, this state of total ignorance about
3.1. Normality
If we are supposing Naturalism, we must suppose that the universe and its constants came about by some natural process. But here’s the thing about natural processes: they don’t tend to give rise to uniform distributions. Consider the distribution of human height (taken from https://ourworldindata.org/human-height):
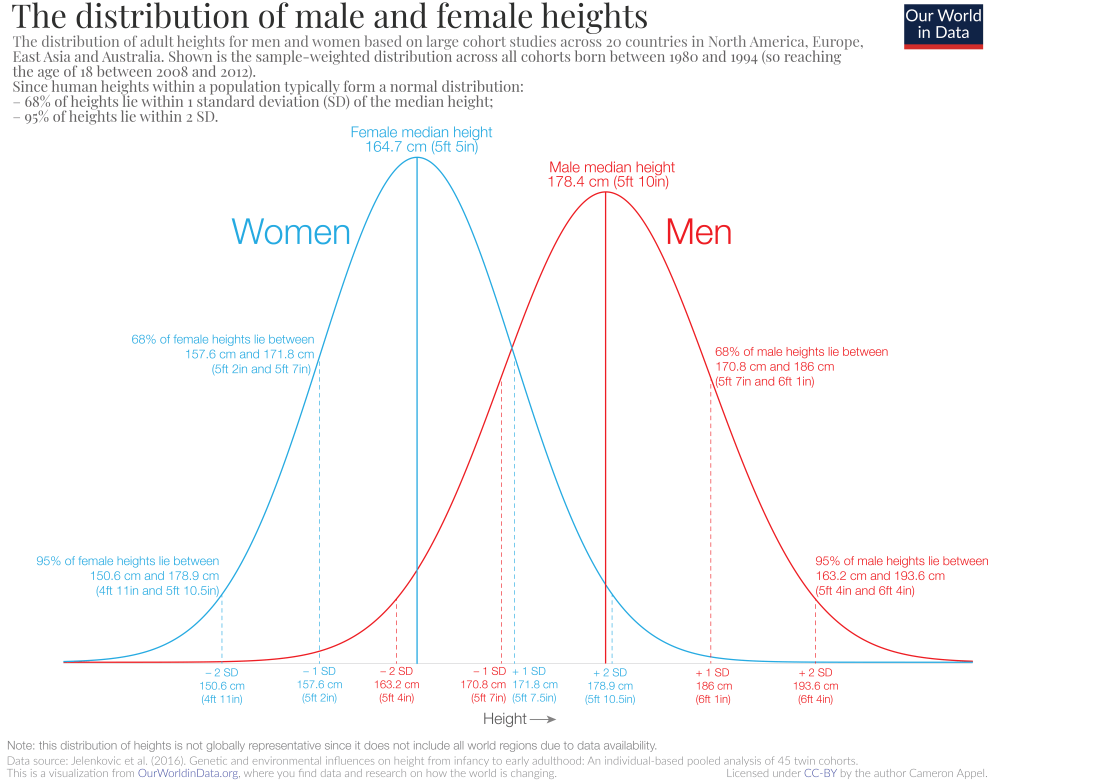
What this is not is a uniform distribution. Instead, it resembles far more a normal distribution. And height is not a cherry-picked example; normal distributions are extremely prevalent among naturally occurring quantities.
Given this, it is reasonable a priori to suppose that 


3.2. An estimate for the mean
At first, this assumption of normality seems to achieve very little. We have no clue what
But there is a flaw in this reasoning: we are not in a situation where the Principle of Indifference applies. We do not have no information at all about the distribution governing our universe: we have a data point. The actual value for
More formally, given the data that
(Bayesians reading this might not approve of using MAP here, in which case we can easily show, and indeed it is visualised in the below figure, that if 

This might be a bit abstract, so lets give an example. Below is a bunch of experiments of random points on the unit circle with argument normally distributed with uniformly random mean (and standard deviation of pi/10) . The red dot indicates the mean value. The orange dot indicates the very first point sampled for each circle.  Notice how the orange dot is a pretty decent estimate for the mean in most of the experiments.
Notice how the orange dot is a pretty decent estimate for the mean in most of the experiments.
4. Conclusion
So, what is the upshot of all this? The argument above aims to show the following:
Given Naturalism, we should infer that the possible values for the constants of the universe are normally distributed with mean the values we observe them as taking.
Given this, it is then no longer clear that on Naturalism it is unlikely that a given constant will fall in the life-permitting range. Whether this is true or not will depend on the width of the life-permitting region relative to the unknown standard deviation 
These difficulties may not be all too insurmountable. This may not be a rebuttal to the fine-tuning argument, but it does at least present an issue with how it is usually formulated, and seems to me to show that arguments based on a direct application of the Principle of Indifference rest on shaky ground.
Post-script
A reasonable objection here is that this argument only considers a single fine-tuned parameter. We made this simplification because Collins does, and because it makes the maths simpler, but what happens if we consider more parameters? The argument still seems to remain intact!
Let us write it as a syllogism:
- If naturalism is true, the vector
of parameters of a random universe obeys the multivariate normal distribution
, where
is the covariance matrix.
- Given an observation
(where
is life-permitting) and uniform prior for
.
- Therefore, our posterior marginal distribution for
.
- Therefore, if naturalism is true and we observe a life-permitting universe, we should infer that a random universe is distributed according to a multivariate normal distribution with a life-permitting mean.
Proof of (2)
We use Bayes’ theorem:

with the constant of proportionality independent of 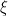

and so

so 
Proof of (3)
This is a bit more involved. We use the fact about the moment-generating function of the multivariate normal that:
![\mathbf{X}\sim\mathcal{N}(\alpha,\Xi) \text{ if and only if } \mathbb{E}_\mathbf{X} [e^{\mathbf{t}^T\mathbf{X}}] = e^{\mathbf{t}^T\alpha + \frac{1}{2} \mathbf{t}^T\Xi \mathbf{t} }.](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BX%7D%5Csim%5Cmathcal%7BN%7D%28%5Calpha%2C%5CXi%29+%5Ctext%7B+if+and+only+if+%7D+%5Cmathbb%7BE%7D_%5Cmathbf%7BX%7D+%5Be%5E%7B%5Cmathbf%7Bt%7D%5ET%5Cmathbf%7BX%7D%7D%5D+%3D+e%5E%7B%5Cmathbf%7Bt%7D%5ET%5Calpha+%2B+%5Cfrac%7B1%7D%7B2%7D+%5Cmathbf%7Bt%7D%5ET%5CXi+%5Cmathbf%7Bt%7D+%7D.%C2%A0+&bg=ffffff&fg=000000&s=1&c=20201002)
The other ingredient we will need is the tower law for conditional expectation:
![\mathbb{E}_\mathbf{X}[f(\mathbf{X})] = \mathbb{E}_\mu[\mathbb{E}_{\mathbf{X}|\mu}[f(\mathbf{X})]].](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%5Cmathbf%7BX%7D%5Bf%28%5Cmathbf%7BX%7D%29%5D+%3D+%5Cmathbb%7BE%7D_%5Cmu%5B%5Cmathbb%7BE%7D_%7B%5Cmathbf%7BX%7D%7C%5Cmu%7D%5Bf%28%5Cmathbf%7BX%7D%29%5D%5D.&bg=ffffff&fg=000000&s=1&c=20201002)
Thus since

![\mathbb{E}_\mathbf{X} [e^{\mathbf{t}^T\mathbf{X}}] = \mathbb{E}_\mu[\mathbb{E}_{\mathbf{X}|\mu}[e^{\mathbf{t}^T\mathbf{X}}]]= \mathbb{E}_\mu[ e^{\mathbf{t}^T\mu + \frac{1}{2} \mathbf{t}^T\Sigma \mathbf{t}} ]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%5Cmathbf%7BX%7D+%5Be%5E%7B%5Cmathbf%7Bt%7D%5ET%5Cmathbf%7BX%7D%7D%5D+%3D+%5Cmathbb%7BE%7D_%5Cmu%5B%5Cmathbb%7BE%7D_%7B%5Cmathbf%7BX%7D%7C%5Cmu%7D%5Be%5E%7B%5Cmathbf%7Bt%7D%5ET%5Cmathbf%7BX%7D%7D%5D%5D%3D+%5Cmathbb%7BE%7D_%5Cmu%5B+e%5E%7B%5Cmathbf%7Bt%7D%5ET%5Cmu+%2B+%5Cfrac%7B1%7D%7B2%7D+%5Cmathbf%7Bt%7D%5ET%5CSigma+%5Cmathbf%7Bt%7D%7D+%5D&bg=ffffff&fg=000000&s=1&c=20201002)
and since
![\mathbb{E}_\mu[ e^{\mathbf{t}^T\mu + \frac{1}{2} \mathbf{t}^T\Sigma \mathbf{t}} ] = e^{\frac{1}{2} \mathbf{t}^T\Sigma \mathbf{t}}\mathbb{E}_\mu[ e^{\mathbf{t}^T\mu} ] = e^{\frac{1}{2} \mathbf{t}^T\Sigma \mathbf{t}}e^{\mathbf{t}^T\mathbf{x} + \frac{1}{2} \mathbf{t}^T\Sigma \mathbf{t}}.](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%5Cmu%5B+e%5E%7B%5Cmathbf%7Bt%7D%5ET%5Cmu+%2B+%5Cfrac%7B1%7D%7B2%7D+%5Cmathbf%7Bt%7D%5ET%5CSigma+%5Cmathbf%7Bt%7D%7D+%5D+%3D+e%5E%7B%5Cfrac%7B1%7D%7B2%7D+%5Cmathbf%7Bt%7D%5ET%5CSigma+%5Cmathbf%7Bt%7D%7D%5Cmathbb%7BE%7D_%5Cmu%5B+e%5E%7B%5Cmathbf%7Bt%7D%5ET%5Cmu%7D+%5D+%3D+e%5E%7B%5Cfrac%7B1%7D%7B2%7D+%5Cmathbf%7Bt%7D%5ET%5CSigma+%5Cmathbf%7Bt%7D%7De%5E%7B%5Cmathbf%7Bt%7D%5ET%5Cmathbf%7Bx%7D+%2B+%5Cfrac%7B1%7D%7B2%7D+%5Cmathbf%7Bt%7D%5ET%5CSigma+%5Cmathbf%7Bt%7D%7D.%C2%A0+&bg=ffffff&fg=000000&s=1&c=20201002)
Thus
![\mathbb{E}_\mathbf{X} [e^{\mathbf{t}^T\mathbf{X}}] = e^{\mathbf{t}^T\mathbf{x} + \frac{1}{2} \mathbf{t}^T(2\Sigma) \mathbf{t}}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%5Cmathbf%7BX%7D+%5Be%5E%7B%5Cmathbf%7Bt%7D%5ET%5Cmathbf%7BX%7D%7D%5D+%3D+e%5E%7B%5Cmathbf%7Bt%7D%5ET%5Cmathbf%7Bx%7D+%2B+%5Cfrac%7B1%7D%7B2%7D+%5Cmathbf%7Bt%7D%5ET%282%5CSigma%29+%5Cmathbf%7Bt%7D%7D+&bg=ffffff&fg=000000&s=1&c=20201002)
and so we have posterior marginal distribution
